
Unlike the science of AI, which has yet to live up to the promise of replicating the human brain, machine learning is changing the way we do everything — from face recognition and social media advertising to medical diagnosis and stock classification.
As so often happens with sophisticated but fashionable ideas, there is some confusion around the concepts of artificial intelligence and machine learning. In 1950 — five full years before the term “artificial intelligence” (AI) was coined — British mathematician Alan Turing introduced a test for determining an intelligent computer: A machine is truly intelligent, he wrote, if a human asking it questions can’t tell the difference between the computer’s answers and those of a human.1
Since then, AI has become an element of popular culture, represented as something that can easily satisfy the Turing test. In Hollywood movies like 2001: A Space Odyssey, the Terminator saga and Her, AI appears almost humanlike. However, Turing’s definition of an intelligent machine is more philosophical than practical.2 What nowadays is referred to as AI usually is mostly based on machine learning technologies. The recent overwhelming achievements of machine learning — spam detection; text, speech and face recognition; medical diagnosis; stock classification; and social media advertising — have nothing to do with the popular perception of AI. The common misunderstanding of the technologies behind these successes has blurred what are purely engineering problems. In this article, we’ll try to dispel the misconceptions and briefly explain some of the most advanced methods of machine learning.
First, it’s important to understand that there is no generally accepted definition of artificial intelligence in modern science.3 You will hardly ever hear the acronym AI used by the scientists and engineers responsible for the technologies behind automated decision making, image recognition or web searching. AI is an extremely wide family of methods and algorithms with one common attribute: All of them were inspired by attempts to understand and reproduce human decision making, human vision and human searching. Indeed, it has always been painful for information scientists that any three-year-old child can immediately distinguish between pictures of a dog and a cat with 100 percent precision, while for computer algorithms this task remains a challenge. The natural reaction to such situations has been, “Let’s just do the same as humans.” But doing the same has appeared to encourage so many different approaches and interpretations that it becomes difficult to describe AI as a well-determined area of knowledge.
Machine learning traces its roots to Frank Rosenblatt, an American psychologist who in 1957 invented the perceptron while working at Cornell Aeronautical Laboratory in Buffalo, New York.4 The idea behind the perceptron was both obvious and promising: Using the assumption that the human brain is nothing but a collection of neurons, Rosenblatt came up with the notion of creating an artificial neuron that would make it “feasible to construct an electronic or electromechanical system which will learn to recognize similarities or identities between patterns of optical, electrical, or tonal information, in a manner which may be closely analogous to the perceptual processes of a biological brain.” An artificial neuron is the simplest linear classifier of input signals and has parameters that can be fit (taught) on a set of training examples. A perceptron is an assembly of artificial neurons that may represent stronger and more complex classifiers. The disadvantage is that having too many parameters may lead to what is called overfitting, when good training results do not imply good results on new data.
The field of machine learning encompasses several families of decision making, optimization and classification algorithms that rely on theory and produce proven results if applied properly. Machine learning can resolve classification tasks (whether the picture shows a dog or a cat) or prediction tasks (trying to determine the price of stocks tomorrow). Its algorithms can usually be trained on a set of examples, applying the knowledge obtained to new data. Here, we give a brief overview of the most developed directions and methods in machine learning.
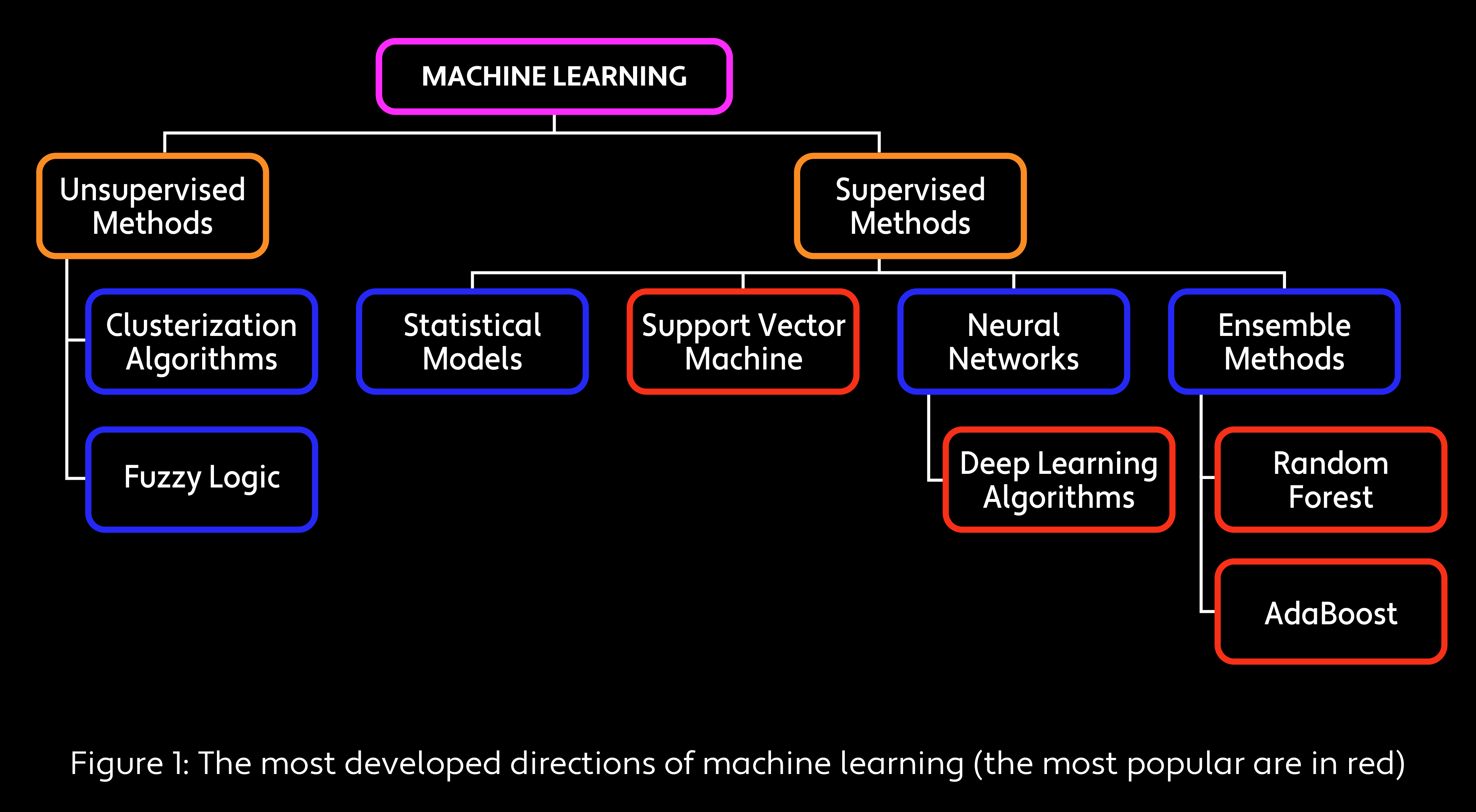
Supervised Learning and Unsupervised Algorithms
In supervised learning, we expect the machine to train itself from the set of examples provided. For instance, in the case of the classification of cats and dogs, we prepare a set of pictures with the correct labels and let the computer teach itself to distinguish between them. By contrast, unsupervised algorithms are used for clustering tasks when we don’t know the correct answers in advance. In this case, the machine search is directed with some predefined quality criteria. For investors, the task of predicting stock prices can be a good application for supervised learning, whereas a machine algorithm that selects stocks for a portfolio will likely be unsupervised.
Fuzzy Logic Methods
In classical logic, every statement is either true or false. In real life, this is not always enough: We can think of some statements that are likely true, indefinite or unlikely true. In other words, there is a gray scale between yes and no. Allowing machines to operate in such an underdefined world, we can produce a whole line of reasoning, called fuzzy logic,5 that has imprecise inference rules and provides mechanisms to make decisions with a lack of information. Fuzzy logic is used in many applications, including face recognition, air conditioners, washing machines, antilock braking systems, subway and unmanned-vehicle controllers, weather forecasting systems, models for new-product pricing or project risk assessment, medical diagnosis and treatment plans, and stock classification. Digital camera autofocus systems are a good example of a simple technical device that is usually based on fuzzy logic.
Statistical Models
Statistical models — hidden Markov, linear discriminant analysis, logistic regression, naive Bayes —are a group of algorithms that are good for solving relatively simple problems that do not need highly precise classification or prediction. These methods are easy to implement and not very sensitive to missing data. The disadvantage is that each of these approaches presumes some specific data model. For example, the naive Bayes method is sometimes used in medical diagnostics to derive the diagnosis from the results of some measurements; it’s critical that all the measurements are independent.
Statistical models constitute the basis of many systems. They are used for classification in various fields, from physics to linguistics to financial forecasting. Naive Bayes models are widely applied in medical diagnostics; hidden Markov models are typically used for voice recognition and natural language processing.6
Support Vector Machine
In the 1960s, Soviet scientists Vladimir Vapnik and Alexey Chervonenkis invented7 the generalized portrait algorithm, which led to the family of classification algorithms known as support vector machine (SVM). The generalized portrait and SVM algorithms were new steps in machine learning. In contrast to Rosenblatt’s perceptron, in SVM the solution presumes the best generalization of the results. In other words, the accuracy achieved during training is preserved off-sample and prevents overfitting.
Unlike many other machine learning algorithms, SVM has a strong theoretical base. It is very robust and has several modifications for various types of problems, but it usually requires a lot of training time and is not ideal for parallel computations — a disadvantage for modern algorithms. SVM is very common in a lot of applications, including handwritten text recognition, classification of images, classification of proteins and genes in biology, and identification of diseases according to symptoms and physical measures.
Neural Networks
The perceptron, which attempted to represent the structure of a human brain with artificial neurons, was a neural network (NN). Scientists later learned that the key to replicating the function of the brain is not the neurons but how we connect them to one another and how we train them. Although there is no theory that can suggest how to build a neural network for any specific task, there is a well-known backpropagation algorithm that allows neural networks to be trained. (Think of a neural network not as a specific algorithm but as a specific way to represent algorithms.)
Neural networks are used in a lot of applications today — most notably, image recognition. But the combination of the lack of theory and the lack of internal transparency of neural networks (their internal logic is hard to interpret) has somewhat held back their development. Nevertheless, neural networks are very efficient for anyone who has access to a supercomputer. They play an important role in many artificial intelligence systems, including computers that beat human players in chess, determine credit ratings and detect fraudulent internet activity.
Ensemble Methods
Ensemble methods like the AdaBoost8 and Random Forest algorithms9 aggregate the solutions of multiple weak classifiers or predictors with poor accuracy to obtain a stronger classification or more precise prediction. The Random Forest algorithm constructs a set of simple decision trees by relying on training examples and then makes these trees vote to obtain the final decision for new cases. AdaBoost (which stands for “adaptive boosting”) aggregates various weak classifiers to obtain a final decision as a weighted combination of weak decisions. These algorithms are very scalable and good for parallel computations, making them a perfect fit for computer vision applications.
Deep Learning
Few areas of machine learning have received more hype than deep learning.10 Some data scientists think deep learning is just a buzzword or a rebranding of neural networks. The name comes from Canadian scientist Geoffrey Hinton,11 who created an unsupervised method known as restricted Boltzmann machine (RBM) for pretraining neural networks with a large number of neuron layers. RBM was meant to improve backpropagation training, but there is no strong evidence that it is really an improvement.
Another alternative direction of deep learning is recurrent neural networks (RNN), which are widely used in voice recognition (“Hello, Siri!”) and natural language processing. More frequently, deep learning is used to refer to the convolutional neural network (CNN).12 The architecture of CNN was introduced originally by Japanese research scientist Kunihiko Fukushima, who developed the neocognitron model (feed-forward neural network) in 1980, and longtime New York University computer scientist Yann LeCun, who modified the backpropagation algorithm for neocognitron training. CNN is ideally suited for computer vision and image recognition applications. It can easily detect shifts within an image, so if we have to recognize, for example, pictures of the same face, CNN doesn’t really care if the face appears in the corner of the image or if it is upside down. Although CNN requires a lot of computational power for training, it can be easily paralleled. Unfortunately, it inherits all the disadvantages of neural networks.
When Alan Turing came up with his test more than 60 years ago to determine whether a machine can think, UNIVAC had just introduced the first tape drive for a commercial computer. Since then, computational power and data storage have increased exponentially, but what is called artificial intelligence is still far — and distinct — from human intelligence. Moreover, although it was originally inspired by human thinking patterns, AI keeps going in a different direction, formalizing problems and employing mathematical logic that is unnatural for human beings. Of course, there is a chance that some future breakthrough in neuropsychology will bring us closer to understanding the internal mechanics and logic of human intelligence so we’ll be able to engineer it, but for now the human brain continues to be one of life’s biggest mysteries. Perhaps machine learning systems — which talk to us, beat us in chess and recognize our faces — can help us tackle the problem.
Michael Kozlov is a Senior Executive Research Director at WorldQuant and has a PhD in theoretical physics from Tel Aviv University.
Avraham Reani is a Senior Regional Research Director at WorldQuant and has a PhD in electrical engineering from Technion.


